This is a follow-up to my previous post about web scraping with Python.
Previously, I wrote a basic intro to scraping data off of websites. Since I wanted to keep the intro fairly simple, I didn't cover storing the data. In this post, I'll cover the basics of writing the scraped data to a flat file and then take things a bit further from there.
Last time, we used the Chicago Reader's Best of 2011 list, but let's change it up a bit this time and scrape a different site. Why? Because scrapers break, so we might as well practice a little bit more by scraping something different.
In this post, we're going to use the data from Chicago Magazine's Best Sandwiches list because ... who doesn't like sandwiches?
If you're new to scraping, it might be a good idea to go back and read my previous post as a refresher as I don't intend to be methodical in this one.
Finding the data
Looking at the list, it's clear everything is in a fairly standard format - each of the sandwiches in the list gets a <div class="sammy"> and each div holds a bit more information - specifically, the rank, sandwich name, location, and a URL to a detailed page about each entry.
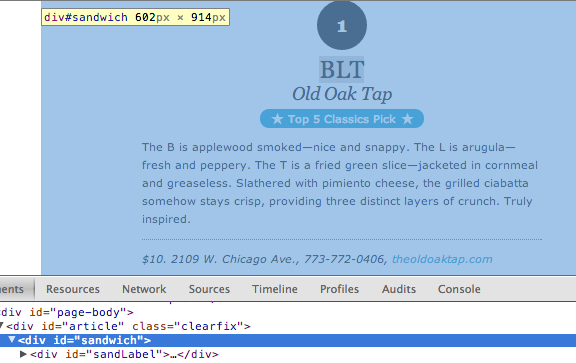
Clicking through a few of the sammy links, we can see that each sandwich also gets a detailed page that includes the sandwich's name, rank, description, and price along with the restaurant's name, address, phone number, and website. Each of these details is contained within <div id="sandwich">, which will make them very easy to get at.
Package choices
We'll again be using the BeautifulSoup and urllib2 libraries. Last time around, the choice of these two libraries generated some discussion in the post's comments section, on Reddit, and Hacker News.
The reason I use BeautifulSoup is because I've found it to be very easy to use and understand, but YMMV. It's been around for a very long time (since 2004) and is certainly in the tool belt of many. That said, Python has a vast ecosystem with a lot of scraping libraries and ones like Scrapy and PyQuery (amongst many others) are worth a look.
Urllib2 is one of Python's URL handling packages within its standard library. Because the standard library has urllib and urllib2, it has at times been confusing to know which is the one you're actually looking for. On top of that, Kenneth Reitz's fantastic requests library exists, which really simplifies dealing with HTTP.
In this example, and in the previous one, I use urllib2 simply because I only need the urlopen function. If this scraper were more complex, I would likely use requests, but I think using a third party library is a bit of overkill for this very simple use case.
Getting the data
Our code this time is going to be very similar to what it was in the previous post, save for a few minor changes. Since the details pages have the data we're looking for, let's get all of their URLs from the initial list page, and then process each details page. We're also going to write all of the data to a tab-delimited file using Python's CSV package.
Last time around, we wrote our code as a set of functions, which I think helps the code's readability since it makes clear what each piece of the code is doing. This time around, we're just going to write a short script since this is really a one-off thing - once we have our data written to a CSV, we don't really have a use for this code anymore.
Our script will do the following:
- Load our libraries
- Read our base_url into a BeautifulSoup object, grab all
<div class="sammy">sections, and then from each section, grab our sammy details URL. - Open up a file named src-best-sandwiches.tsv for writing. We'll write to this file using Python's csv.writer object and separate the fields by a tab (\t). We'll also pass in a list of field names so that our file has a header row.
- Loop through all of our sammy details URLs, grabbing each piece of information we're interested in, and writing that data to our src-best-sandwiches.tsv file.
from bs4 import BeautifulSoup
from urllib2 import urlopen
import csv
base_url = ("http://www.chicagomag.com/Chicago-Magazine/"
"November-2012/Best-Sandwiches-Chicago/")
soup = BeautifulSoup(urlopen(base_url).read())
sammies = soup.find_all("div", "sammy")
sammy_urls = [div.a["href"] for div in sammies]
with open("data/src-best-sandwiches.tsv", "w") as f:
fieldnames = ("rank", "sandwich", "restaurant", "description", "price",
"address", "phone", "website")
output = csv.writer(f, delimiter="\t")
output.writerow(fieldnames)
for url in sammy_urls:
url = url.replace("http://www.chicagomag.com", "") # inconsistent URL
page = urlopen("http://www.chicagomag.com{0}".format(url))
soup = BeautifulSoup(page.read()).find("div", {"id": "sandwich"})
rank = soup.find("div", {"id": "sandRank"}).encode_contents().strip()
sandwich = soup.h1.encode_contents().strip().split("<br/>")[0]
restaurant = soup.h1.span.encode_contents()
description = soup.p.encode_contents().strip()
addy = soup.find("p", "addy").em.encode_contents().split(",")[0].strip()
price = addy.partition(" ")[0].strip()
address = addy.partition(" ")[2].strip()
phone = soup.find("p", "addy").em.encode_contents().split(",")[1].strip()
if soup.find("p", "addy").em.a:
website = soup.find("p", "addy").em.a.encode_contents()
else:
website = ""
output.writerow([rank, sandwich, restaurant, description, price,
address, phone, website])
print "Done writing file"
While our scraper does a good job of getting all of the sandwiches and restaurants, a couple of restaurants had "multiple locations" listed as their address. If we were to need this data, we'll have to find another way to get it (like checking each restaurant's website and manually adding their locations to our dataset). We'll also need to manually fix some oddities that wound up in our data due some inconsistent HTML on the other end (addresses and URLs winding up in the phone numbers column).
We're now left with a file full of data about Chicago Magazine's fifty best sandwiches. Sure, it's nice to have the data structured neatly in a flat file, but that's not all that interesting.
Collecting and hoarding data isn't of use to anyone - it's a waste of a potentially very valuable resource - it needs to be taken a step further. In some cases, this means a thorough analysis in search of patterns and trends, surfacing relationships we did not necessarily expect, and utilizing that information to better our decision-making. Data should be used to inform. In some cases, even a very basic visualization of the data can be of use.
Since we have addresses for each restaurant, this seems like a great time to make a map, but first, geocoding!
Geocoding
We're going to make our map using the Google Maps API, but in order to do so, we're first going to need to geocode our addresses to a set of lat/long points. Don't worry, I've taken the time to manually fill in the blanks on those "multiple locations" restaurants (you can grab the new file from my GitHub repo - it's called best-sandwiches.tsv).
To do so, we'll just write a short Python script which hits the Google Geocoding API. Our script will do the following:
- Read our best-sandwiches.tsv file using the CSV module's DictReader class, which reads each line of the file into its own dictionary object.
- For each address, make a call to the Google Geocoding API, which will return a JSON response full of details about that address.
- Using the DictWriter class, write a new file with our data along with the formatted address, lat, and long that we got back from the geocoder.
from urllib2 import urlopen
import csv
import json
from time import sleep
def geocode(address):
url = ("http://maps.googleapis.com/maps/api/geocode/json?"
"sensor=false&address={0}".format(address.replace(" ", "+")))
return json.loads(urlopen(url).read())
with open("data/best-sandwiches.tsv", "r") as f:
reader = csv.DictReader(f, delimiter="\t")
with open("data/best-sandwiches-geocode.tsv", "w") as w:
fields = ["rank", "sandwich", "restaurant", "description", "price",
"address", "city", "phone", "website", "full_address",
"formatted_address", "lat", "lng"]
writer = csv.DictWriter(w, fieldnames=fields, delimiter="\t")
writer.writeheader()
for line in reader:
print "Geocoding: {0}".format(line["full_address"])
response = geocode(line["full_address"])
if response["status"] == u"OK":
results = response.get("results")[0]
line["formatted_address"] = results["formatted_address"]
line["lat"] = results["geometry"]["location"]["lat"]
line["lng"] = results["geometry"]["location"]["lng"]
else:
line["formatted_address"] = ""
line["lat"] = ""
line["lng"] = ""
sleep(1)
writer.writerow(line)
print "Done writing file"
Our file now has everything we need to make our map, which we're able to do with some basic HTML, CSS, JavaScript, and a little Google Fusion Tables magic.
Mapping
While we could write another Python script to turn our flat file data into KML for mapping, it's much, much easier to use Google Fusion Tables. However, one important note with the Fusion Tables approach is that the underlying data must be within a public Fusion Table. Since our data is scraped from a publicly accessible website, that's not an issue here.
If you don't see Fusion Table as an option in your Google Drive account, you'll need to "connect more apps" and add it from there.
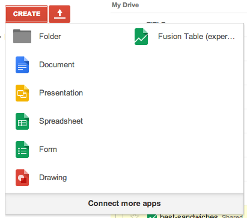
Once you've added the app, create a new Fusion Table from the delimited file on your computer (our best-sandwiches-geocode.tsv).
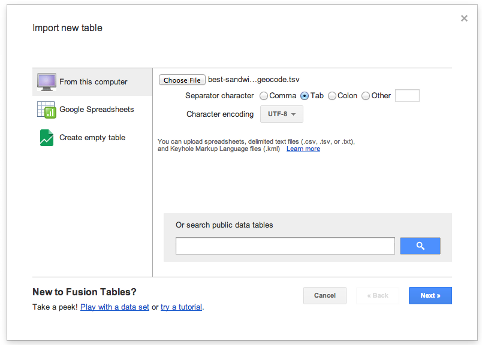
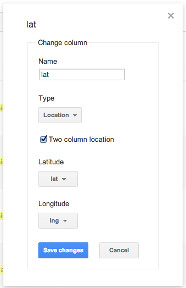
After you've finished your upload process, you should now have a spreadsheet-like table with the data in it. You'll notice that some of the columns are highlighted in yellow - this means that Fusion Tables is recognizing that it's a location. Our lat and lng columns should be all the way at the right - hover over the lat column header and select change from the drop down. This should display a prompt showing us the column type is a two column location comprised of both our lat and lng.
This is probably where I should point out that we could have also used Fusion Tables to geocode our data, but writing a script in Python seemed like more fun to me.
Now that we have our data successfully in the Fusion Table, we can use a combination HTML, CSS, some JavaScript, and the Fusion Tables API to serve up a map (you could also just click the map tab in Fusion Tables to see an embedded map of the data, but that's not as fun). We can even style the map with the Google Maps Style Wizard.
Head over to my GitHub repo to see the HTML, CSS, and JavaScript used to create the map (along with the rest of the code and data used throughout this post). I've done my best to comment the best-sandwiches.html file to indicate what each piece is doing. I've also used HTML5's geolocation capabilities so that fellow Chicagoans can easily see which sandwiches are near them (it displays pretty nicely on a mobile browser, too).
You can check out the awesome map we made here. Note that if you aren't in Chicago and let your browser know your location, you likely won't see any of the data - you'll have to scroll over to Chicago.
Hopefully you found this post fun and informative. Was there something I didn't cover? Let me know in the comments.