This is part of a series of posts I have written about web scraping with Python.
- Web Scraping 101 with Python, which covers the basics of using Python for web scraping.
- Web Scraping 201: Finding the API, which covers when sites load data client-side with Javascript.
- Asynchronous Scraping with Python, showing how to use multithreading to speed things up.
- Scraping Pages Behind Login Forms, which shows how to log into sites using Python.
The other day a friend asked whether there was an easier way for them to get 1000+ Goodreads reviews without manually doing it one-by-one. It sounded like a fun little scraping project to me.
One small complexity was that the user's book reviews were not public, which meant you needed to log into Goodreads to access them. Thankfully, with a little understanding of how HTML forms work, Python's requests library makes this doable with a few lines of code.
This post walks through how to tackle the problem. If you'd like to jump straight to the code, you can find it on my Github.
While we'll use Goodreads here, the same concepts apply to most websites.
First, you'll need to dig into how the site's login forms work. I find the best way to do this is by finding the page that is solely for login. Here's an example from Goodreads:
From there, you'll need to find the necessary details of the login form. While this will include some sort of username/email and password, it will likely include a token and possibly other details.
The best way to find these details is by launching your browser's developer tools inside one of the input fields (like username/email). This will bring you to the code that is responsible for the form and allow you to find the details required.
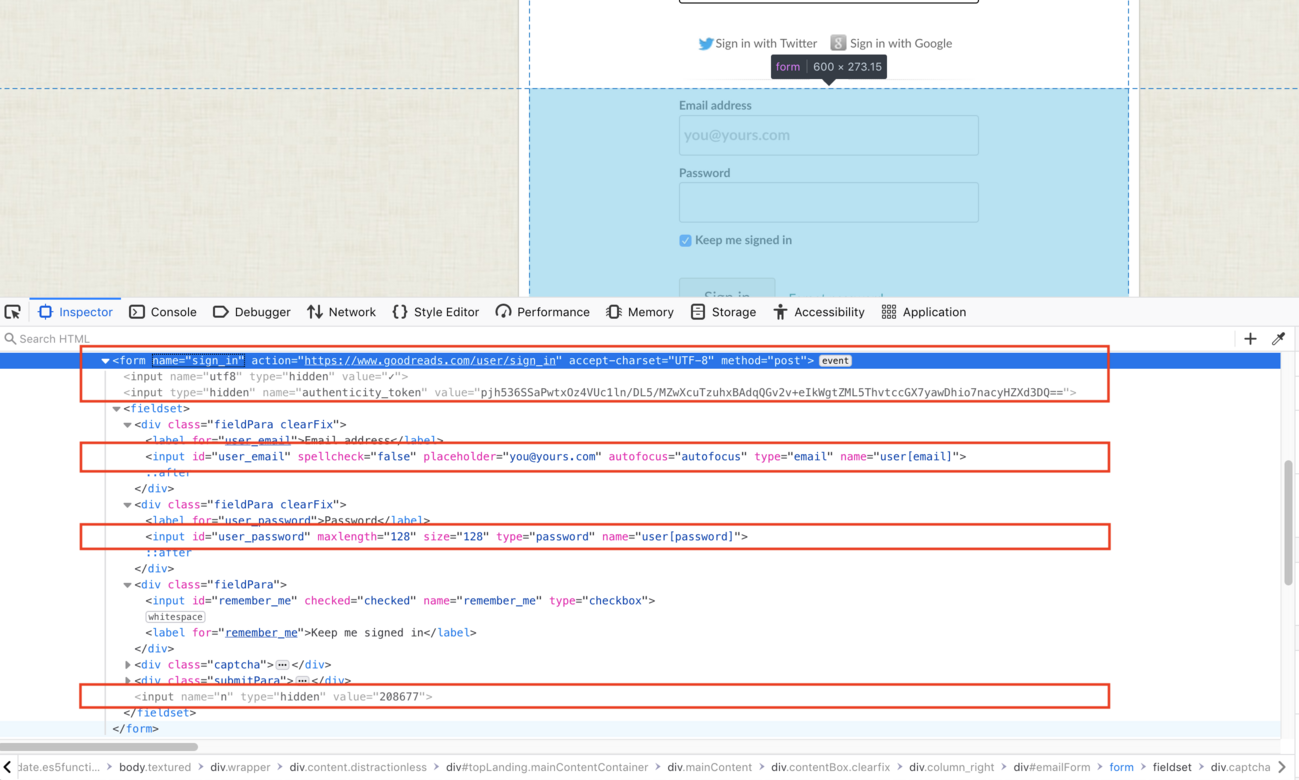
Using the screenshot above as an example, we can see the form requires some user input fields and as well as some hidden fields:
- A hidden
utf8field with a checkmark value. The checkmark value will be converted to its HTML hexcode on submission, which is✓. - A hidden
authenticity_tokenwith a provided value. - A
user[email]which is input via the form. - A
user[password]which is input via the form. - A hidden
nfield with a provided value.
When you enter your email and password into the form and press login, the first line in the highlighted red box tells us that the form data is sent via an HTTP POST request to https://www.goodreads.com/user/sign_in (seen in the method and action fields, respectively). The user and password fields are then checked against the site's database to validate the information. Essentially, it's saying "Here are the credentials I was given. Is this a valid user?" If the credentials are valid, you are redirected to some page within the app (like the user's home page).
Once login is successful, a cookie is then stored in your browser's memory. Every time you access one of the site's pages, the site checks to make sure the cookie is valid and that you are allowed to access the page you are trying to reach.
To scrape data that is behind login forms, we'll need to replicate this behavior using the requests library. In particular, we'll need to use its Session object, which will capture and store any cookie information for us.
from bs4 import BeautifulSoup
import requests
LOGIN_URL = "https://www.goodreads.com/user/sign_in"
def get_authenticity_token(html):
soup = BeautifulSoup(html, "html.parser")
token = soup.find('input', attrs={'name': 'authenticity_token'})
if not token:
print('could not find `authenticity_token` on login form')
return token.get('value').strip()
def get_login_n(html):
soup = BeautifulSoup(html, "html.parser")
n = soup.find('input', attrs={'name': 'n'})
if not n:
print('could not find `n` on login form')
return n.get('value').strip()
email = "some@email.com" # login email
password = "somethingsecret" # login password
payload = {
'user[email]': email,
'user[password]': password,
'utf8': '✓',
}
session = requests.Session()
session.headers = {'User-Agent': ('Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) '
'AppleWebKit/537.36 (KHTML, like Gecko) Chrome/85.0.4183.121 Safari/537.36')}
response = session.get(LOGIN_URL)
token = get_authenticity_token(response.text)
n = get_login_n(response.text)
payload.update({
'authenticity_token': token,
'n': n
})
print(f"attempting to log in as {email}")
p = session.post(LOGIN_URL, data=payload) # perform login
If the POST request in the last line is successful, our session object should now contain a cookie that allows us to programmatically access the same pages that our user normally has access to. We'll simply need to request these pages using session.get and then can proceed as I've previously detailed.
You can find the complete code for this post on my Github.